NIM : 23018553755
A. Kegunaan Struct Dalam Bahasa Pemrograman serta Linked List
Salah satu tipe data dalam bahasa C adalah struct. Struct merupakan tipe data yang mengumpulkan tipe data yang lain. Tipe data yang bisa dimasukkan adalah int,float,char,double,dll. kegunaan struct dalam bahasa c yaitu menampung berbagai tipe data agar mudah terlihat dan diatur serta memudahkan programmer untuk mendeklarasikan tipe data yang dimasukkan dalam struct. kegunaan struct bisa dipakai berbagai macam seperti daftar nama mahasiswa,dosen,guru,karyawan. Dalam penggunaan struct, ada kemiripan dengan penggunaan array dimana masing-masing tipe data dapat menampung jumlah data yang banyak sehingga tidak perlu membuat banyak variabel. Tetapi, struct dan Array memiliki perbedaan yang signifikan dimana array hanya bisa menampung satu tipe data seperti array yang hanya mengandung nama saja, tetapi struct bisa menampung berbagai tipe data sehingga lebih mudah terlihat.
Cara pendeklarasian struct dalam bahasa C adalah :
struct nama_variabelstruct{
tipe_data1 variabelstruct;
tipe_data2 variabelstruct;
tipe_data3 variabelstruct;
.
.
.
};
lalu untuk deklarasi dalam main adalah dengan cara :
struct nama_variabel_struct nama_variabel.
struct nama_variabel_struct nama_variabel.
Dan untuk inputan untuk memanggil dengan cara :
nama_variabel.variabelstruct;
nama_variabel.variabelstruct;
Linked list merupakan struktur data yang terdiri atas beberapa node yang merepresentasikan sebuah urutan. Linked list menggunakan struct untuk pendeklarasian linked list. struktur sederhana linked list adalah:
struct node {
int value;
struct node *next;
};
B. Linked List
Dalam pelajaran kelas CB01 Data Structure hari ini, kita belajar mengenai Single Linked List.
Single Linked List adalah banyaknya data yang saling berhubungan satu dengan yang lain dimana setiap node memiliki alamat node yang lain dan bersifat satu arah dimana node hanya mengetahui alamat node yang lain, bukan alamat node yang ditanya. Kita bisa meng-analogikan seperti aku menanyakan kepada John alamat Bill dan John yang mengetahui alamat Bill bisa memberitahukan kita alamat Bill tetapi John tidak tahu alamat kita. Jika dalam analogi ini JOhn mengetahui alamat aku maka itu bisa disebut dengan Double Linked List.
Single Linked List memiliki beberapa bagian :
1. Head = bagian awal dari rantai Linked List.
2. Tail = bagian akhir dari rantai Linked List.
3. NULL = bagiam setelah Tail yang bernilai NULL/0
Dalam mengerjakan Single Linked List, ada beberapa metode dalam mengupdate sebuah Linked List.ada beberapa seperti :
1. Insert/Push : kata-kata ini biasanya dipakai untuk menambahkan sebuah node yang belum berada dalam sebuah linked list ke dalam rantai linked list.
2. Delete/Pop: kegunaannya adalah untuk menghapus node yang berada dalam sebuah rantai Linked List
Ada beberapa metode yang bisa dilakukan dalam melakukan insert/ push maupun delete/pop seperti:
a. Depan/Head : menambah/menghapus node kedepan sebuah rangkai Linked List.
b. Belakang/Tail : menambah/menghapus node ke bagian paling belakang sebuah rantai Linked List.
c. Mid : menambah/menghapus node yang berada di tengah Tail dan Head.
Contoh code untuk Linked List:
#include <stdio.h>
#include<stdlib.h>
struct data{
int value;
struct data *next;
}*head,*tail,*curr;
void insertFront(int x){
struct data *node = (struct data*)malloc(sizeof(struct data));
node->value = x;
if(head == NULL){
head = tail = node;
tail->next;
}
else{
node->next = head;
head = node;
}
}
void insertBack(int x){
struct data *node = (struct data*)malloc(sizeof(struct data));
node->value = x;
if(tail == NULL){
head = tail = node;
tail->next;
}
else{
tail->next=node;
tail=node;
tail->next=NULL;
}
}
void delHead(){
curr = head;
head = curr->next;
free(curr);
}
void delTail(){
curr = head;
while(curr!=NULL){
if(curr->next==tail) break;
else curr = curr->next;
}
tail = curr;
free(tail->next);
tail->next = NULL;
}
void insertBefore(int x, int p){
struct data *node = (struct data*)malloc(sizeof(struct data));
node->value = x;
curr=head;
while(curr->next->value!=p) curr=curr->next;
node->next = curr->next;
curr->next = node;
}
void view(){
curr=head;
while(curr!=NULL){
printf("%d",curr->value);
if(curr->next!=NULL) printf(" ");
else printf("\n");
curr = curr->next;
}
}
int main (){
insertFront(5);
insertFront(6);
insertFront(1);
insertBack(9);
insertBack(7);
view();
insertBefore(3,6);
view();
return 0;
}
C. Hashing Table and Binary Tree
Sebelum kita masuk dalam Hashing Table dan Binary Tree, saya akan menjelaskan pengertian dan cara kerja double pointer. Double pointer adalah pointer yang menunjuk kepada sebuah pointer yang lain. Dimana, pointer pertama menunjuk pada lokasi alamat sebuah variabel dan pointer kedua menunjukkan kepada alamat pada pointer pertama. Cara mendeklarasi sebuah double pointer adalah:
B. Linked List
Dalam pelajaran kelas CB01 Data Structure hari ini, kita belajar mengenai Single Linked List.
Single Linked List adalah banyaknya data yang saling berhubungan satu dengan yang lain dimana setiap node memiliki alamat node yang lain dan bersifat satu arah dimana node hanya mengetahui alamat node yang lain, bukan alamat node yang ditanya. Kita bisa meng-analogikan seperti aku menanyakan kepada John alamat Bill dan John yang mengetahui alamat Bill bisa memberitahukan kita alamat Bill tetapi John tidak tahu alamat kita. Jika dalam analogi ini JOhn mengetahui alamat aku maka itu bisa disebut dengan Double Linked List.
Single Linked List memiliki beberapa bagian :
1. Head = bagian awal dari rantai Linked List.
2. Tail = bagian akhir dari rantai Linked List.
3. NULL = bagiam setelah Tail yang bernilai NULL/0
Dalam mengerjakan Single Linked List, ada beberapa metode dalam mengupdate sebuah Linked List.ada beberapa seperti :
1. Insert/Push : kata-kata ini biasanya dipakai untuk menambahkan sebuah node yang belum berada dalam sebuah linked list ke dalam rantai linked list.
2. Delete/Pop: kegunaannya adalah untuk menghapus node yang berada dalam sebuah rantai Linked List
Ada beberapa metode yang bisa dilakukan dalam melakukan insert/ push maupun delete/pop seperti:
a. Depan/Head : menambah/menghapus node kedepan sebuah rangkai Linked List.
b. Belakang/Tail : menambah/menghapus node ke bagian paling belakang sebuah rantai Linked List.
c. Mid : menambah/menghapus node yang berada di tengah Tail dan Head.
Contoh code untuk Linked List:
#include <stdio.h>
#include<stdlib.h>
struct data{
int value;
struct data *next;
}*head,*tail,*curr;
void insertFront(int x){
struct data *node = (struct data*)malloc(sizeof(struct data));
node->value = x;
if(head == NULL){
head = tail = node;
tail->next;
}
else{
node->next = head;
head = node;
}
}
void insertBack(int x){
struct data *node = (struct data*)malloc(sizeof(struct data));
node->value = x;
if(tail == NULL){
head = tail = node;
tail->next;
}
else{
tail->next=node;
tail=node;
tail->next=NULL;
}
}
void delHead(){
curr = head;
head = curr->next;
free(curr);
}
void delTail(){
curr = head;
while(curr!=NULL){
if(curr->next==tail) break;
else curr = curr->next;
}
tail = curr;
free(tail->next);
tail->next = NULL;
}
void insertBefore(int x, int p){
struct data *node = (struct data*)malloc(sizeof(struct data));
node->value = x;
curr=head;
while(curr->next->value!=p) curr=curr->next;
node->next = curr->next;
curr->next = node;
}
void view(){
curr=head;
while(curr!=NULL){
printf("%d",curr->value);
if(curr->next!=NULL) printf(" ");
else printf("\n");
curr = curr->next;
}
}
int main (){
insertFront(5);
insertFront(6);
insertFront(1);
insertBack(9);
insertBack(7);
view();
insertBefore(3,6);
view();
return 0;
}
C. Hashing Table and Binary Tree
Sebelum kita masuk dalam Hashing Table dan Binary Tree, saya akan menjelaskan pengertian dan cara kerja double pointer. Double pointer adalah pointer yang menunjuk kepada sebuah pointer yang lain. Dimana, pointer pertama menunjuk pada lokasi alamat sebuah variabel dan pointer kedua menunjukkan kepada alamat pada pointer pertama. Cara mendeklarasi sebuah double pointer adalah:
int **variabel;
Hash adalah mengubah input dengan panjang berapapun dan memberikan output dengan panjang yang tetap. Output dengan panjang yang tetap biasanya menggunakan algoritma seperti SHA-256 yang berarti hasil output panjangnya tetap yaitu sepanjang 256-bit. Fungsi hash adalah menjaga keamanan sebuah inputan agar hasilnya tidak bisa dibaca orang yang tidak memiliki otoritas.
Hash Table atau yang bisa disebut dengan Pohon Merkle dimana setiap simpul non daun adalah hasil hash dari nilai simpul anaknya. node daun adalah node terendah dari sebuah pohon, root node adalah node teratas dari sebuah node dan dibawah root node adalah node anak.
Blockchain adalah daftar tertaut yang berisi data dari pointer hash yang menunjuk ke blok sebelumnya dimana cara kerja seperti double pointer yang sudah dijelaskan diatas. pointer hash bukan hanya berisi alamat dari blok tersebut tetapi juga berisi hash didalam blok tersebut. Hal ini menyebabkan jika ada perubahan dalam sebuah blok maka blok lain akan berubah juga.Apakah hashing table terpakai dalam blockchain? tentu saja, karena dalam sebuah blok berisi ribuan transaksi dan tidak efisien jika setiap data dalam blok disimpan dalam seri. maka menggunakan pohon merkle dalam blockchain mengurangi waktu yang diperlukan untuk mengetahui apakah sebuah transaksi berada dalam sebuah blok dimana kita bisa track dari transaksi di dalam sebuah blok dengan mengikuti jejak hash yang akan mengarah ke data.
Binary tree adalah tree dalam data structure dimana sebuah node memiliki anak yang dimana node anak maksimal memiliki 2 node yaitu anak kiri dan anak kanan.fungsi binary tree adalah sebagai akses node bedasarkan sebuah value dan representasi data dengan struktur bifurkasi yang relevan
D. Binary Search Tree
Binary Search Tree adalah salah satu cara penyimpanan data dengan menggunakan metode tree/pohon yang dimana setiap node maksimal hanya boleh memiliki 2 anak node. dalam binary search tree, terdapat beberapa aturan yaitu :
1. nilai node anak bagian kiri selalu lebih kecil dari node parent
2. nilai node anak bagian kanan selalu lebih besar dari node parent
3.bagian kiri atau kanan node sebuah anak bisa menjadi sebuah node parent dimana BST memiliki sifat Rekursif
4. Setiap node memiliki nilai value dan tidak ada node yang bernilai sama/ double
Ada 3 operasi yang bisa dilakukan dalam BST yaitu :
A. Searching Data: mencari value x di dalam BST ( Find(x))
Terdapat 3 cara untuk melakukan searching data dalam BST yaitu :
1. Pre-Order : dimana print data terlebih dahulu lalu menelusuri node dari kiri ke kanan
2. InOrder : menelusuri node dari kiri lalu print data lalu kembali menelusuri node di kanan
3. Post-Order : menelusuri node dari kiri ke kanan lalu print data.
B. Insert Data : memasukan value baru x ke dalam BST (Insert(x))
Langkah-langkah yang dilakukan untuk insert data adalah :
1. dimulai dari node root
2. jika x lebih kecil dari node parent maka akan dimasukan ke node anak bagian kiri secara berulang (rekursif)
3. jika x lebih besar dari node parent maka akan dimasukkan ke node anak bagian kanan secara berulang (rekursif)
4. Dilakukan pengulangan sampai terdapat node yang kosong untuk memasukan value x
C. Delete Data : Menghapus value x dari BST (Delete(x))
terdapat 3 kasus dalam delete data yaitu :
1. jika value yang dihapus adalah leaf maka langsung dihapus
2. jika value yang dihapus hanya memiliki 1 node anak maka hapus nodenya dan node anaknya digabung dengan node parentnya
3. jika value memiliki 2 node anak maka ada 2 cara dimana bisa mencari left node paling terakhir ( leaf) atau bagian kanan node menggantikan menjadi parent node
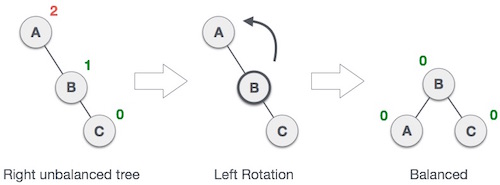
E. AVL Tree
AVL Tree adalah salah satu bentuk dari Binary Search Tree. Yang menyebabkan AVL Tree berbeda adalah AVL Tree memiliki perbedaan tinggi antara subtree kiri dengan kanan maksimal satu atau perbedaan tingginya bisa memiliki tinggi yang sama. Hal ini untuk mempersingkat waktu pencarian serta mempersingkat dan menyerdehanakan bentuk tree.
D. Binary Search Tree
Binary Search Tree adalah salah satu cara penyimpanan data dengan menggunakan metode tree/pohon yang dimana setiap node maksimal hanya boleh memiliki 2 anak node. dalam binary search tree, terdapat beberapa aturan yaitu :
1. nilai node anak bagian kiri selalu lebih kecil dari node parent
2. nilai node anak bagian kanan selalu lebih besar dari node parent
3.bagian kiri atau kanan node sebuah anak bisa menjadi sebuah node parent dimana BST memiliki sifat Rekursif
4. Setiap node memiliki nilai value dan tidak ada node yang bernilai sama/ double
Ada 3 operasi yang bisa dilakukan dalam BST yaitu :
A. Searching Data: mencari value x di dalam BST ( Find(x))
Terdapat 3 cara untuk melakukan searching data dalam BST yaitu :
1. Pre-Order : dimana print data terlebih dahulu lalu menelusuri node dari kiri ke kanan
2. InOrder : menelusuri node dari kiri lalu print data lalu kembali menelusuri node di kanan
3. Post-Order : menelusuri node dari kiri ke kanan lalu print data.
B. Insert Data : memasukan value baru x ke dalam BST (Insert(x))
Langkah-langkah yang dilakukan untuk insert data adalah :
1. dimulai dari node root
2. jika x lebih kecil dari node parent maka akan dimasukan ke node anak bagian kiri secara berulang (rekursif)
3. jika x lebih besar dari node parent maka akan dimasukkan ke node anak bagian kanan secara berulang (rekursif)
4. Dilakukan pengulangan sampai terdapat node yang kosong untuk memasukan value x
C. Delete Data : Menghapus value x dari BST (Delete(x))
terdapat 3 kasus dalam delete data yaitu :
1. jika value yang dihapus adalah leaf maka langsung dihapus
2. jika value yang dihapus hanya memiliki 1 node anak maka hapus nodenya dan node anaknya digabung dengan node parentnya
3. jika value memiliki 2 node anak maka ada 2 cara dimana bisa mencari left node paling terakhir ( leaf) atau bagian kanan node menggantikan menjadi parent node
E. AVL Tree
AVL Tree adalah salah satu bentuk dari Binary Search Tree. Yang menyebabkan AVL Tree berbeda adalah AVL Tree memiliki perbedaan tinggi antara subtree kiri dengan kanan maksimal satu atau perbedaan tingginya bisa memiliki tinggi yang sama. Hal ini untuk mempersingkat waktu pencarian serta mempersingkat dan menyerdehanakan bentuk tree.
Insertion
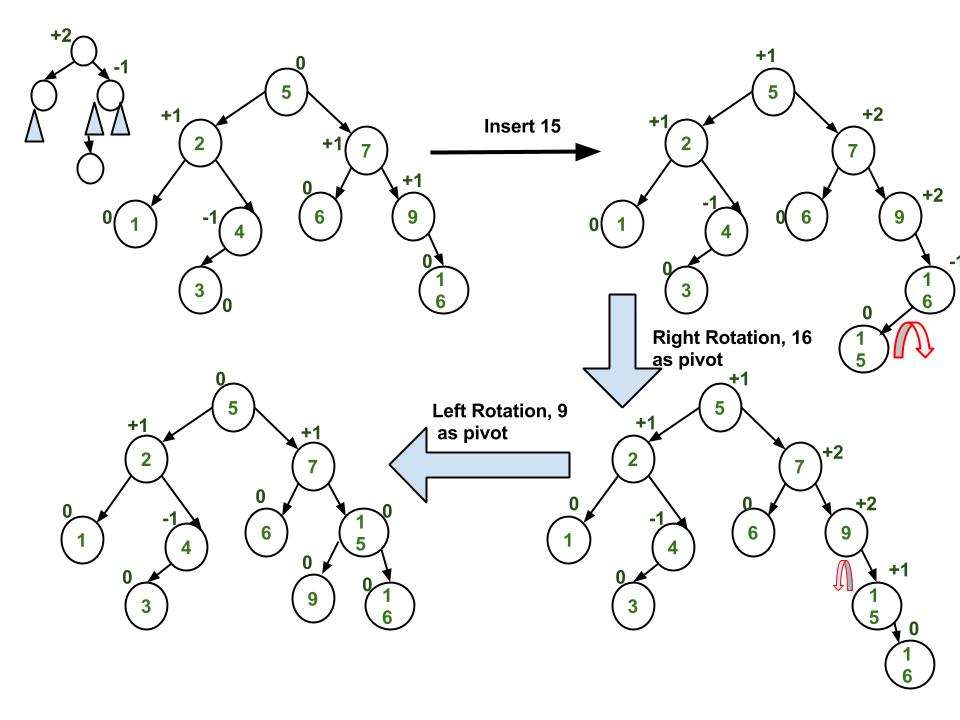
Seperti Binary Search Tree pada umumnya, AVL Tree juga memiliki operasi insertion, bedanya terletak pada jenisnya. Terdapat 2 jenis Insertion yaitu :
1. Single Rotation
operasi insertion ini bisa dilakukan pada node terdalam pada subtree kiri dan anak kiri dan juga pada subtree kanan dan anak kanan ( operasi ini dilakukan jika memasukan node pada tree yang berurutan seperti gambar diatas)
2. Double Rotation
operasi insertion ini dilakukan pada node terdalam pada subtree kiri dan anak kanan serta subtree kanan dan anak kiri.
Deletion
untuk menghapus node pada AVL Tree memiliki kasus yang serupa dengan Binary Seach Tree yang normal, yaitu :
a. jika node yang akan dihapus terletak pada leaf (node tanpa anak) maka akan langsung terhapus
b. jika node yang akan dihapus terletak pada node dengan anak maka harus diseimbangkan dengan menyesuaikan tinggi dengan perbedaan 1 tinggi dengan menggunakan single atau double rotation
F. Heaps and Tries
Heaps adalah salah satu bentuk tree yang memenuhi syarat heap, yaitu anak dari sebuah node, maka node tersebut nilainya harus lebih besar atau sama dengan anak node tersebut disebut max-heap. jika anak node lebih besar atau sama dengan node tersebut maka disebut min-heap. gabungan dari kegunaan max-heap dan min-heap disebut dengan min-max heap dimana dalam baris node atas lebih kecil dari node bawahnya lalu node bawahnya lagi lebih besar dan seterusnya.
 Tries adalah pohon struktur data yang terurut yang menyimpan data array. Penggunaan tries biasanya digunakan pada web browser dalam bentuk autocomplete dan juga melakukan autocorrect. pada tree ini, node yang berada di paling atas menjadi huruf awal dan node anaknya menjadi huruf-huruf berikutnya
Tries adalah pohon struktur data yang terurut yang menyimpan data array. Penggunaan tries biasanya digunakan pada web browser dalam bentuk autocomplete dan juga melakukan autocorrect. pada tree ini, node yang berada di paling atas menjadi huruf awal dan node anaknya menjadi huruf-huruf berikutnya
F. Heaps and Tries
Heaps adalah salah satu bentuk tree yang memenuhi syarat heap, yaitu anak dari sebuah node, maka node tersebut nilainya harus lebih besar atau sama dengan anak node tersebut disebut max-heap. jika anak node lebih besar atau sama dengan node tersebut maka disebut min-heap. gabungan dari kegunaan max-heap dan min-heap disebut dengan min-max heap dimana dalam baris node atas lebih kecil dari node bawahnya lalu node bawahnya lagi lebih besar dan seterusnya.
